Analog-to-Digital Conversion
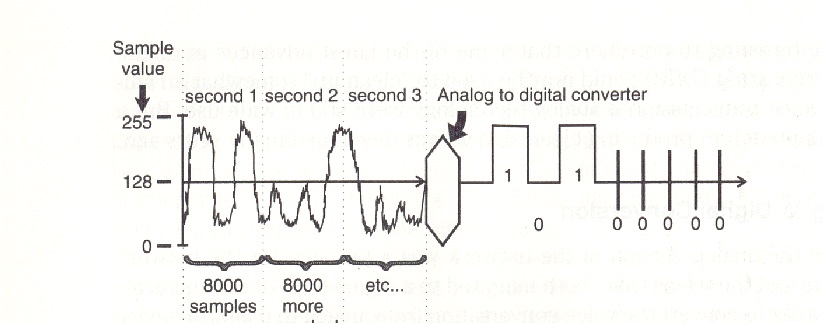
Because the analog version of the network was a problem for the network suppliers and the telcos alike, both migrated to a digital form of communicating. In order to convert the voice conversation from analog to digital, a device called an analog-to-digital (A/D) converter employs a sampling technique. Sampling refers to the process of measuring (see how we are creeping up on quantifying a signal?) representative portions of a signal over time. We make the assumption that chronologically adjacent portions will differ only slightly. If the samples are taken frequently enough, and played back faithfully at the other end, the ear will not be able to differentiate the playback from the original. A (nondigital) sampling technique is used in movies and other video applications. When a movie is made, there is no truly continuous record of the images; instead, a series of still images, sampling the reality at 30 samples Cor frames) per second, is recorded and later presented to the viewer.
Normally, the viewer cannot distinguish between playback of the samples and the real thing. As mentioned earlier, the bandwidth of the audio signal we wish to transmit is 3000 hertz (3300 minus 300). Based on the Nyquist theorem (which states that one should sample at a rate at least twice the maximum frequency of the line), the minimum sampling rate would be 6600 hertz (2 times the 3300 Hz). In fact, a somewhat higher rate of 8000 hertz (samples per second), is used. This is used to address the higher range of frequencies on a conversation, such as those SSS and FFF sounds that were filtered out in the analog world. Each sample measures the amplitude level of the voice signal at a particular point in time.
One sample comprises eight bits, where a bit represents a one or a zero. An eight-bit character or byte can represent any decimal number from 0 to 255 (00000000 is zero, 00000001 is one, 00000010 is two, 00000011 is three, 0000100 is four, 0000101 is five, and so on up to 11111111 which equals 255). Therefore, there are a total of 256 possible levels, sufficient enough to recreate the analog signal in good faith at the receiving end. More sample values would produce a higher-quality replication, but the ear is not sensitive enough to discern the differences. Eight thousand samples per second, where each sample requires eight bits, generates a digital stream of data at the rate of 64,000 bits per second. We know this as the digital signal 0 (DSO), the digitized equivalent of one voice channel. The bits are each in the form of a square wave, as contrasted to the familiar sinusoidal wave that is typically seen on an oscilloscope.
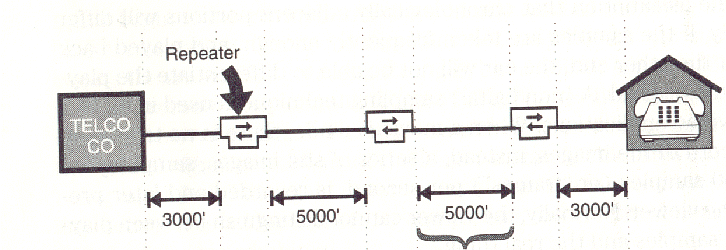
During the analog-to-digital conversation, Repeaters are stationed at approximately each mile of line. A sampling rate of 8000 hertz is used between the telephone company and the end user. Digitization The PCM conversion between analog and digital can be done in one step, within a single integrated circuit chip, the codec (COder-DECoder). Traditionally, it is done in two steps.
1. Pulse amplitude modulation.
2. Digital encoding.
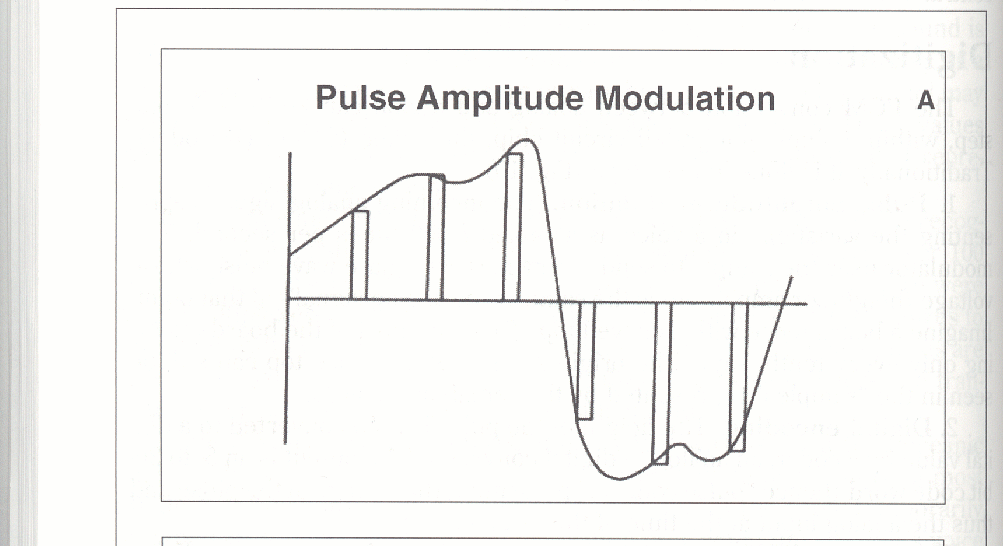
The one-step PCM process converts an analog voice signal to a digital stream of 64,000 bits per second (bit/s); 8 bits per sample x 8,000 samples/sec. The rate of 8,000 samples per second comes from the Nyquist theorem. This theorem shows that an analog reconstruction from digital data can contain all the information of the original analog signal if the sampling rate is faster than two times the highest frequency in the original signal. In other words, if enough fence boards remain. Technically, sampling must detect every change in direction (up to down or the reverse), or every change in sign of the analog signal (positive to negative or the reverse). If sampling is not rapid enough, the resulting digitized points can represent more than one analog signal. This phenomenon is aliasing and produces unintelligible sounds.
To avoid aliasing, voice inputs are low-pass filtered to block any appreciable amount of signal at a frequency above 4,000 Hz. The filter adversely affects adjacent frequencies. The usable upper limit is only 3,300 Hz. Filtering out the low end, to block 60 Hz hum from power lines, puts the practical lower limit at 300 Hz. The size of the sample, 8 bits, was determined after considerable experimentation, and a large amount of invention. The problem was to optimize the trade-off between bit rate and voice quality. It didn’t hurt that computers then were starting to deal with 8-bit characters. An analog signal, by definition, has infinite variability—it can take on any value. The digital representation of the same signal can take on only a relatively small number of discrete values, limited by the number of bits per sample: 8 bits allow 255 values.
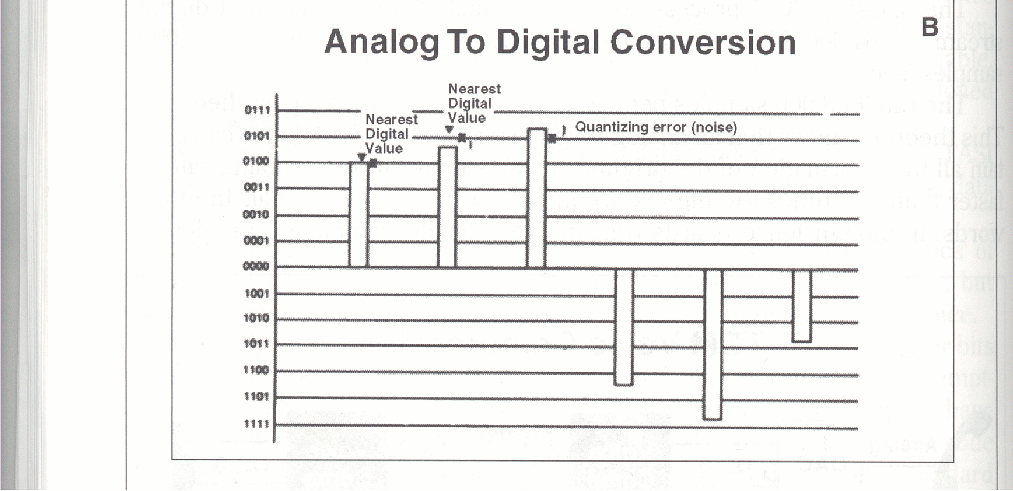
Therefore, at the precise time of a sampling, the analog input is seldom exactly the same as one of the possible digital output steps. The CODEC, however, must make a selection, and will pick the closest digital value. The difference between analog input and digital measurement (between the dot and the X in the PCM drawing above) is digitizing distortion, or quantizing noise. The human ear is very sensitive to quantizing noise. The distortion sounds bad. The quantizing process can be compared to someone measuring the height of the boards in a fence to the nearest foot when the length could vary an inch. Early listening tests showed that if the analog input were measured with many digital output values very close together, the quantizing noise could be reduced to where it was not important. Unfortunately, the number of digital values required to cover the full volume range of a voice signal in such small steps is at least +/- 2,000. This is like measuring the fence height in millimeters. To number that many steps requires 12 to 16 or more bits per sample. At 8,000 PCM voice samples per second, that would be at least 96,000 bit/s. Hi Fi codecs in stereo equipment may use 16,18. or more bits per sample, and 44,000 samples per second. That’s per stereo channel. CDs sound better than a telephone. The price is higher bandwidth: not very hard to get if you stay in one box; too expensive for telephone calls.
Even 25 years ago, when T-1 was introduced, designers recognized the possibility of compressing voice. They simply gave less attention to the very loudest levels. That is, by concentrating the digital measurement steps in the low and normal volume range, they reduced the number of steps needed for toll quality to 256 (an 8-bit binary word). In effect, the quantizing noise was kept very small at low volume levels, but allowed to increase with loudness. The effect is masked by other distortions created by the microphone, receiver, and lines when the volume is high. For simplicity, the first analog to digital conversion is linear, into a binary number with 12, 14, 16, or more bits. Then the processor converts that large binary number to an 8-bit number by using a conversion table.
To concentrate the measuring at the low end of a range produces a highly non-linear ruler To measure a fence with it, some graduations might be 1 mm apart; others, as much as 1 foot apart. Voice engineers designed a non- linear voice ruler with the fineness of an adequate linear rule (16-bits) near zero, and wider spacing at louder levels. This technique needs only 8 bits to measure pulse heights over the full volume range of a voice. In other words, a non-linear voice encoder saves at least 33% of the digital bandwidth.
The original signal is compressed for transmission, then expanded at the receiving end to the full 14- or 16-bit range. The two-phase process is known as companding. Thus PCM, today’s standard, is itself a form of voice compression. The specific form of non-linearity is the ‘mu-law’ algorithm in North America and Japan (T-1 regions), ‘A-law’ in the rest of the world (where E-1 is used). Differences arise in how the linear ruler is segmented to correspond to the nonlinear ruler (which ranges of 16-bit numbers map to which 8-bit numbers). The two tables are only slightly different. Most central office switches convert between the two companding laws. But if a switch neglects to perform the conversion, voice transmission still takes place in an understandable way—you might not even notice if speaking with a stranger.

This introduction is meant to teach you about the functions and technology of a Central Office.
Sound
Analog to Digital
Bandwidth
Facilities Network
Traffic Networks
Public Switched
The Telephone Network
A Topology of Connection
Network Hierarchy (pre 1984)
Network Hierarchy (post 1984)
North American Numbering Plan
International Numbering
The Subscriber Extension
Private Networks
Hybrid Networks
Local Access and Transport Areas
Wiring Connections: Hooking Things Up
Types of Communication
Signaling (SS7)
Lines Vs. Trunks
Loop Start
Calling Procedures
Ground Start
E&M Signaling
Foreign Exchange Signal
DID
DOD
FX
OPX
Wats